论文:Manifold: A Model-agnostic Framework for Interpretation and Diagnosis of Machine Learning Models
作者:Jiawei Zhang, Yang Wang, Piero Molino, Lezhi Li, David S. Ebert. 1 作与 5 作来自于 Purdue University, 其余来自 Uber 公司.
发表: IEEE VIS 2018, VAST / TVCG
简介
近年来在机器学习领域上有了不少重大的突破, 很多场景应用中都有了巨大的进展. 但是这也带来了一些问题, 首先, 模型越发复杂, 让模型开发者很难解释为什么模型会起作用, 以及它们是如何运作的; 其次, 开发者没有可靠的证据或者推理来指引他们开发与调试, 这导致模型开发这样一个迭代过程十分耗时、容易出错.
可视化与交互界面在帮助用户将自己知识结合进解读和诊断模型的过程中去. 常见的解决方案包括, 通过可视化模型内部结构或者状态来增强用户理解与解释, 评估分析算法和模型的性能, 在模型开发不同环节加入交互成分(如超参调试, 特征工程过程中加入领域知识). 但这些模型的关注点都在某些特定模型类别上或者特定任务类型(如 classification). 这些工作缺乏可扩展性, 很难对付 industry-level 的使用场景, 因为这种场景下模型和任务的体积与复杂度都非常大.
本文提出框架 Manifold 来解决整合、评估和调试多个模型的问题. 这个框架的设计过程结合了机器学习诊断与比较时常用的三个阶段: 检视(假设), 解释(推理)和改良(校验). 为了支持这些阶段, Manifold 提供了两个简洁而丰富的视图: 基于散点图的模型比较视图, 提供一个模型对(model pairs)丰富性与互补性的可视总结. 用户可以在这个视图上找到有问题的数据自己并提出假设. 第二个是一个表格形式的视图, 帮助用户区分从有问题的数据子集中抽出的不同特征, 哪些特征对模型输出有更大的影响, 并提出对于之前猜想的解释. 随后这些解释又可以被加如到下一轮迭代中去来验证和改良模型.
Manifold 是 model-agnostic 的, 这个词的意思是无所谓你模型长什么样, 只要你有一样的任务, 一样的输入输出就可以了. Manifold 不需要接触模型内部的 logic.
相关工作
模型解读与性能分析、交互模型改良与模型集成
动机与设计目标
机器学习研究者遇到的挑战
- 孤立的看一个模型 | 将其与其他模型比较,来理解一个模型的优劣
- 模型比较与集成 (model ensembling)
- 将前面获得的 insights 结合进模型开发迭代中
可视化设计者的设计任务
Inspection (Hypothesis)
- 大致了解某个模型好不好
- 聚焦于某个特定数据子集
Explanation (Reasoning)
- 理解 instance-level 与 feature-level 的细节信息
- 进行大量比较分析
Refinement (Verification)
可视设计
系统概览如下, 左边是 model comparison view, 右边是 feature interpretation view.
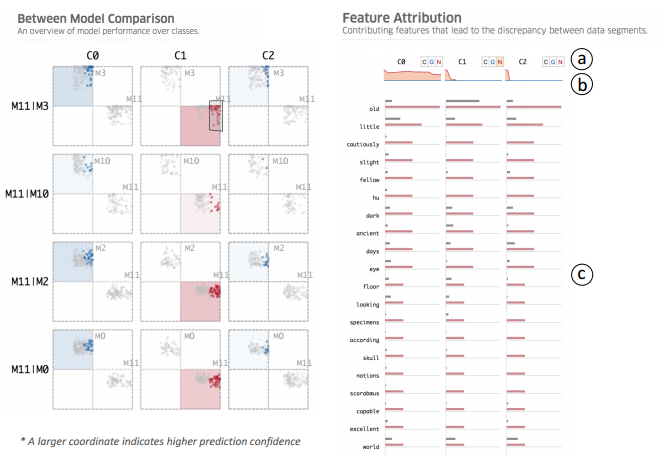
注意: Manifold 可以用于分类以及回归任务, 设计一致, 但是编码上略有不同, 这里仅仅用分类作为例子.
Model Comparison View
左边每个 cell 其编码的含义如下 (我们考虑一个多分类的分类问题, 每个数据会对应一个标签 C_i (如 C_0, C_1, C_2 表示有三个分类); 然后我们有不同的模型 M_i):
如图 cell, 展示的是模型 M_i, M_j 与所分类标签 C_i.
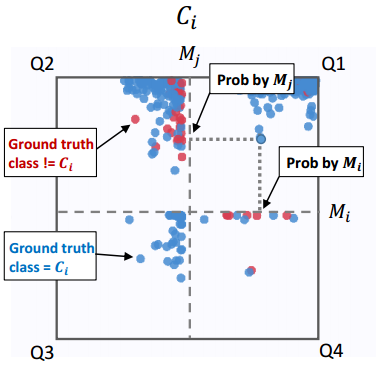
每个点代表一个 input 的数据实例; 坐标代表预测为该类的置信度(越靠近原点置信度越低); 正负轴代表对于数据点的预测结果是否是 C, 所以第一象限和第四象限意味着是被 Mi 预测为 Ci 的, 但第四象限意味着被 Mj 预测为其他类的; ‘点的颜色含义: 预测的分类与 ground truth 一致是蓝色, 否则是红色.
但这张图展现的不仅于此, 还有展现了如下两种量: 模型的 correctness, 即 true positive, false positive 等等. 以及两个模型 M_i, M_j 在预测上是否一致: 一三象限代表是一致的. 此外, 若点太多太密集的话, cell 中还提供了轮廓图的选项.
在这个视图中, 还提供了一系列的 filter 操作, 分别是在 cell (small multiple)上和在数据上. 前者包括: 横着切片, 观察一个模型和其他模型; 竖着切片, 只看几类; 选取单个 cell. 后者包括: ALL, UNION (ALL 除开 true negative 数据)和 ground truth 三个; 还可以用象限选择以及 lasso 选择数据点.
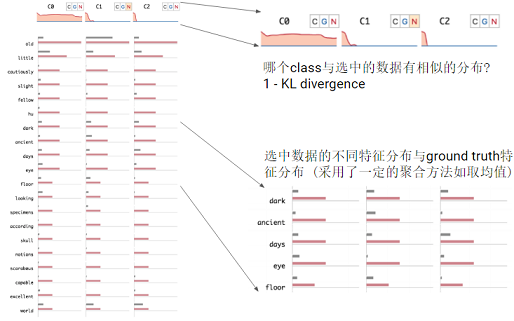
Feature Interpretation View
当我们在上个视图中选择了一个数据子集, 就可以在 feature interpretation view 里进行更多的 feature-level 的探索分析.
Case study
文章用文本分类(多类回归)与共享单车需求预测(回归)来展现了 Manifold 的实战分析, 详细内容比较复杂有兴趣的读者请见原文. 他们用两个 cases 体现了如下的 workflow.
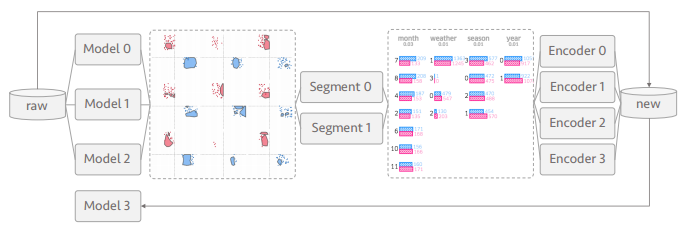
前面没有太多提到最后如何应用前两阶段所得来 verification 和 refinement, 其实有这么一些步骤, 如模型集成(ensemble), 或用一些发现的模式生成新的特征放进模型重新训练看看是否提升
专家点评
除了专家的夸赞以外, 我还注意到这两点: (1) 模型比较视图的学习曲线是比较高的, 专家也认为; 通过一定的训练就能理解掌握 (2) 专家称, 在评估和调试模型的时候, 得到 feature-level 的 insighs 已经足够为特征工程和模型迭代提供引导了. 所以他们也觉得 manifold 通过可视比较实现这个目标很好.
个人总结
- 设计简洁, 但又丰富, 又能适应专家需求
- 我们常说 open the box, 但本文反其道而行之, close the black box, 这个思路也是一种创新. 尽管在模型微调方面应用不大
- model agnostic 的分析方法从 KDD 16 时候的 LIME 开始带动了热潮; 可视化领域今年一篇 RuleMatrix 也是一种 model agnostic 的形式, 但是那篇文章提到了, 我不是为了给机器学习专家, 只是为了领域专家在了解机器学习模型时候提供一些帮助. 这个切入点也很棒, 值得学习.
✉️ akiori@zju.edu.cn